
蓝:宏病毒知识点
一 概述
宏病毒是一种常见的计算机病毒,寄存在文档或模板中,但是并不会直接感染可执行程序。其诞生于上世纪90年代,自其诞生之日,各种各样的宏病毒不断在网络上涌现。早期的宏病毒是病毒先驱者们展现高超技术的舞台,只感染文档文件,随着时间的推移,宏病毒的危害也越来越大,宏病毒不再只是感染文档文件,而成为了分发恶意程序的常规途经。宏病毒的执行简易隐蔽快速,一旦用户打开含有宏病毒的文档,其中的宏病毒就会被执行。
对于攻击者而言,宏病毒是一把利器,尤其是结合了社会工程学的宏病毒。如乌克兰电网事件(BlackEnergy),工作人员只是打开了一篇看似很正常的文档,然后便造成了无法挽回的损失。不只是BlackEnergy,近来肆虐的各种各样的勒索软件,都离不开Office宏的帮助。借助传统的宏病毒,一旦用户打开含有宏病毒的文档,其中的宏病毒就会被执行,释放并激活恶意软件。
二 基础知识
1. 宏与宏病毒
宏(英文Macro),广义上的定义是:宏就是把一系列的指令组织成一独立的命令,类似C语言中#define宏定义,避免同一动作的一再重复;狭义上,宏特指office系列办公软件中的宏,Microsoft Office中对宏的定义为“宏就是能够组织在一起的,可以作为一个独立命令来执行的一系列Word命令,它能使日常工作变得容易。”本文中提到的宏,采用了狭义的定义,即office办公软件中的宏。
使用office文档文件(demo1.doc)时,有时候我们会遇到如下图所示的“安全警告”,这说明
该文档文件中含有宏,并且office软件设置了“宏禁用”功能。
这个时候,单击“启用内容”按钮,宏就会执行。使用快捷键Alt+F11可以打开vb编辑器,查看宏代码。

宏病毒是使用宏语言编写的恶意程序,存在于字处理文档、电子数据表格、数据库、演示文档等数据文件中,可以在office系列办公软件中运行,利用宏的功能将自己复制到其他数据文件中。宏病毒感染的是数据文件。宏病毒与传统的病毒有很大的不同,它不感染可执行文件,而是潜伏在Microsoft Office文档中,一旦用户打开含有宏的文档,其中的宏就会被执行。宏是使用VBA编写的,编写过程简单,任何人只需掌握一些基本的宏编写技能就可以编写出破坏力巨大的宏病毒。
宏病毒的强大是建立在强大的VBA组件的基础上的。同时,宏病毒与系统平台无关,任何计算机如果能够运行Microsoft Office办公软件,都有可能感染宏病毒。随着Microsoft Office系列办公软件成为电子文档的工业标准,Word,Excel和PowerPoint等已成为个人计算机和互联网上广泛使用的文档格式,宏病毒成为传播最广泛,危害最大的一类病毒。
根据文档载体的不同,宏病毒可以细分为很多种,Word、Excel、Access、PowerPoint等都有
想应的宏病毒。
2. 启用宏
打开包含恶意宏代码的文档,ALT+F11打开VBA编辑器,查看宏代码。但是你会发现,此时工程里没有数据,这是因为我们没有单击“启用内容”,VBA工程还没有加载。单击“启用内容”,这个时候宏就已经运行了,再次查看VBA编辑器,就可以查看到宏代码。
2.1 破解宏密码保护
2.1.1 VBA_Password_Bypasser
官方网址:http://download.canadiancontent.net/VBA_Password_Bypasser_(TSVPB).html
关闭文档,使用VBA_Password_Bypasser打开文档,再次打开VBA编辑器就可以查看宏代码。
2.1.2 手动破解
将该文件重命名为zip文件,双击压缩包,找打压缩包内的vbaProject.bin文件。使用notepad++打开找到DPB部分。
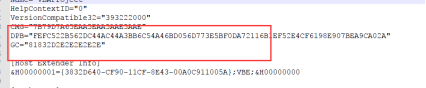
将DPB更改为DPBx(随意),保存后重新放入到压缩包内,并将压缩包还原为xlsm文件。
双击打开文件,ALT+F11进入宏代码窗口,右键属性。
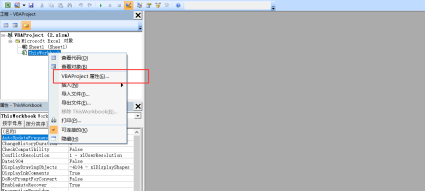
找到保护,填入新的账号密码。

再次双击,即可查看宏代码

2.2 使用脚本提取宏代码
在之前的分析中,我们先启用宏,然后打开VBA编辑器分析宏代码。这个时候我们不仅可以直观的看到宏代码,还可以动态调试。但是,我们选择启用宏后,宏代码就会运行,如果存在恶意行为,恶意行为就会执行。这样的分析方式存在一定的风险。
oledump.py(https://github.com/decalage2/oledump-contrib) 是一个用于分析OLE文件(复合文件二进制格式)的程序,我们可以使用它提取文档中的宏代码。其查找基于二进制文件格式的文件中的内容的流程:
- 读取文件流
- 识别可能包含要查找的内容的结构
- 通过第一个结构,找到下一节的位置
- 在流中转到该节
- 重复前面两个步骤,直到找到所需的内容
- 读取并分析内容
3. 宏病毒分析技巧
3.1 自动执行
宏病毒分析的第一步是定位自动执行入口。
宏病毒具有自动执行的特性,特别是含有AutoOpen的宏,一旦用户打开含有宏的文档,其中的宏就会被执行,而用户一无所知。
宏病毒的激发机制有三种:
- 利用自动运行的宏
- 修改Word命令
- 利用Document对象的事件
宏病毒中常用的自动执行方法有两种:
- 用户执行某种操作时自动执行的宏,如Sub botton(),当用户单击文档中的按钮控件时,宏自动执行
- Auto自动执行,如Sub AutoOpen()和Sub AutoClose(),分别在文档打开和关闭时自动执行
3.2 隐秘执行
宏病毒利用几行代码就可以实现隐秘,下列代码是从宏病毒样本1(MD5:f849544803995b98342415dd2e67180c)中提取的代码片段,宏病毒通过阻止弹出各类提示,防止用户发现宏正在运行来实现自我隐藏:
| On Error Resume Next | 如果发生错误,不弹出错误对话框 |
| Application.DisplayStatusBar = False | 禁止显示状态栏 |
| Options.SaveNormalPrompt = False | 修改公用模板时自动保存,不弹出提示 |
宏病毒自我隐藏还有一种方式,那就是屏蔽菜单按钮和快捷键,普通用户即使猜测到有宏正在运行,也无法取消正在执行中的宏以及查看宏信息。
宏病毒采取的隐蔽执行的一些措施:
| On Error Resume Next | 如果发生错误,不弹出错误对话框 |
| Application.DisplayStatusBar = False | 不显示状态栏,避免显示宏的运行状态 |
| Options.SaveNormalPrompt = False
EnableCancelKey = wdCancelDisabled |
修改公用模板时在后台自动保存,不给任何提示
使不可以通过ESC键取消正在执行的宏 |
| Application.ScreenUpdating = 0 | 不让屏幕更新,让病毒执行时不影响计算机速度 |
| Application.DisplayAlerts=wdAlertsNone | 不让Excel弹出报警信息 |
| CommandBars(“Tools”).Controls(“Macro”).Enabled = 0 | 屏蔽工具菜单中的“宏”按钮 |
| CommandBars(“Macro”).Controls(“Security”).Enabled= 0 | 屏蔽宏菜单的“安全性” |
| CommandBars(“Macro”).Controls(“Macros”).Enabled = 0 | 屏蔽宏菜单的“宏” |
| CommandBars(“Tools”).Controls(“Customize”).Enabled = 0 | 屏蔽工具菜单的“自定义” |
| CommandBars(“View”).Controls(“Toolbars”).Enabled = 0 | 屏蔽视图宏菜单的“工具栏” |
| CommandBars(“format”).Controls(“Object”).Enabled = 0 | 屏蔽格式菜单的“对象” |
3.3调用外部例程和命令执行
宏病毒的强大主要来自与对Windows API和外部例程的调用,以下是总结出一张宏病毒调用的外部例程表。
| MSXML2.ServerXMLHTTP | Xmlhttp是一种浏览器对象,可用于模拟http的GET和POST请求 |
| Net.WebClient | 提供网络服务 |
| Adodb.Stream | Stream流对象用于表示数据流。配合XMLHTTP服务使用Stream对象可以从网站上下载各种可执行程序 |
| Wscript.shell | WScript.Shell是WshShell对象的ProgID,创建WshShell对象可以运行程序、操作注册表、创建快捷方式、访问系统文件夹、管理环境变量 |
| Poweshell | PowerShell.exe 是微软提供的一种命令行shell程序和脚本环境 |
| Application.Run | 调用该函数,可以运行.exe文件 |
| WMI | 用户可以利用 WMI 管理计算机,在宏病毒中主要通过winmgmts:\\.\root\CIMV2隐藏启动进程 |
| Shell.Application | 能够执行sehll命令 |
3.4 字符串隐写
宏病毒分析比较简单,这是因为任何能执行宏的用户都能查看宏源码,分析人员轻而易举就分析出宏病毒的行为。通过扫描宏中特征字符串,杀软也很容易检测出宏病毒。宏病毒的开发者们便想尽办法隐藏这些特征字符串,下面本文就对宏病毒中这些字符串的隐写方式进行分析。
3.4.1 Chr()函数
Chr(),返回以数值表达式值为编码的字符(例如:Chr(70)返回字符‘F’)。 使用Chr函数是最常见的字符串隐写技术,利用ascii码,逃避字符串扫描。
Chr()函数还可以利用表达式,增加技术人员的分析难度:
Ndjs = Sgn(Asc(317 – 433) + 105)
ATTH = Chr(Ndjs) + Chr(Ndjs + 12) + Chr(Ndjs + 12) + Chr(Ndjs + 8)
经过分析发现,上述代码的字符串是:“http://”
3.4.2 Replace() 函数
Replace函数的作用就是替换字符串,返回一个新字符串,其中某个指定的子串被另一个子串替换。
3.4.3 CallByname() 函数
CallByname函数允许使用一个字符串在运行时指定一个属性或方法。
CallByName 函数的用法如下:
Result = CallByName(Object, ProcedureName, CallType, Arguments())
CallByName 的第一个参数包含要对其执行动作的对象名。
第二个参数,ProcedureName,是一个字符串,包含将要调用的方法或属性过程名。CallType 参数包含一个常数,代表要调用的过程的类型:方法 (vbMethod)、property let (vbLet)、property get (vbGet),或property set (vbSet)。最后一个参数是可选的,它包含一个变量数组,数组中包含该过程的参数。
例如:CallByName( Text1, “Move”, vbMethod, 100, 100)就相当于执行Text1.Move(100,10)
这种隐藏的函数执行增加了分析的难度。
CallByName的作用不仅仅在此,在下面的这个例子中,利用callByName,可以用脚本控制控件:
Dim obj As Object[/align] Set obj = Me
Set obj = CallByName(obj, “Text1”, VbGet)
Set obj = CallByName(obj, “Font”, VbGet)
CallByName obj, “Size”, VbLet, 50
‘以上代码=”Me.Text1.Font.Size = 50″
Dim obj As Object
Dim V As String
Set obj = Me
Set obj = CallByName(obj, “Text1”, VbGet)
Set obj = CallByName(obj, “Font”, VbGet)
V = CallByName(obj, “Size”, VbGet)
‘以上代码=”V = Me.Text1.Font.Size”
3.4.4 Alias替换函数名
Alias子句是一个可选的部分,用户可以通过它所标识的别名对动态库中的函数进行引用。
Public Declare Function clothed Lib “user32” Alias “GetUpdateRect” (prestigiation As Long, knightia As Long, otoscope As Long) As Boolean。
如上例所示,clothed作为GetUpdateRect的别名,调用clothed函数相当于调用user32库里的GetUpdateRect函数。
事实上喜欢使用别名的不仅仅是宏病毒制造者,普通的宏程序员也喜欢使用别名。使用别名的好处是比较明显的,一方面Visual Basic不允许调用以下划线为前缀的函数,然而在Win32
API函数中有大量C开发的函数可能以下划线开始。使用别名可以绕过这个限制。另外使用别名有利于用户命名标准统一。对于一些大小写敏感的函数名,使用别名可以改变函数的大小写。
3.4.5 利用窗体、控件隐藏信息
控件在宏程序里很常见,有些宏病毒的制造者们便想到利用控件隐藏危险字符串。
控件里存放着关键字符串,程序用到上述字符串时,只需要调用标签控件的caption属性。
控件的各个属性(name、caption、controtiptext、等)都可以成为危险字符串的藏身之所。
而仅仅查看宏代码,分析者无法得知这些字符串内容,分析者必须进入编辑器查看窗体属性, 这大大增加了分析的难度。


3.4.6 利用文件属性
这种方式和利用窗体属性的方式类似,就是将一切能存储数据的地方利用起来。
如图所示读取的是ActiveDocument.BuiltinDocumentProperties Comments的数据,实际上就
是文件备注信息里的数据,将这里的数据Base64解密并执行。

4. 恶意行为字符串
不同的宏病毒执行不同的恶意行为,但这些恶意行为是类似的,它们使用的代码往往是相似
的。以下总结了一些宏病毒执行危险操作时代码中含有的字符串,详见下表:
| http | URL连接 |
| CallByName | 允许使用一个字符串在运行时指定一个属性或方法,许多宏病毒使用CallByName执行危险函数 |
| Powershell | 可以执行脚本,运行.exe文件,可以执行base64的命令 |
| Winmgmts | WinMgmt.exe是Windows管理服务,可以创建windows管理脚本 |
| Wscript | 可以执行脚本命令 |
| Shell | 可以执行脚本命令 |
| Environment | 宏病毒用于获取系统环境变量 |
| Adodb.stream | 用于处理二进制数据流或文本流 |
| Savetofile | 结合Adodb.stream用于文件修改后保存 |
| MSXML2 | 能够启动网络服务 |
| XMLHTTP | 能够启动网络服务 |
| Application.Run | 可以运行.exe文件 |
| Download | 文件下载 |
| Write | 文件写入 |
| Get | http中get请求 |
| Post | http中post请求 |
| Response | http中请求回复 |
| Net | 网络服务 |
| WebClient | 网络服务 |
| Temp | 常被宏病毒用于获取临时文件夹 |
| Process | 启动进程 |
| Cmd | 执行控制台命令 |
| createObject | 宏病毒常用于创建进行危险行为的对象 |
| Comspec | %ComSpec%一般指向你cmd.exe的路径 |
三 宏病毒处理
目前主流杀软在处理宏病毒时,都是直接删除含有宏病毒的文档,这样处理显得有些粗暴,将导致用户无法查看文档里的数据,如果是一些重要的业务数据,将造成业务数据的丢失,产生无法估计的后果。本文将介绍一种宏病毒处理思路,在不删除文档文件的情况下清除宏病毒。
在正式处理宏病毒前,我们必须对Office文档的数据结构以及宏的数据结构有着初步的了解。
1. Office文档与宏的数据结构
1.1 复合文档(OLE文件)二进制解析
1.1.1 复合文档数据结构解析
Office文档(如:.doc、.ppt、.xls等)很多是复合文档(OLE文件),所有文件数据都是存
储在一个或多个流中。每个流都有一个相似的数据结构,用于存储元数据的数据结构。这些元数据有用户和系统的信息、文件属性、格式信息、文本内容、媒体内容。宏代码信息也是以这种方式存储在复合文档中的。
为了在Office文档文件中提取出宏代码,必须能够解析复合文档的二进制格式,下面以word为例,分析复合文档的二进制结构。
许多用户在新建word文档时会发现有两个选项,新建Microsoft Word 97 – 2003 文档和新建
新建 Microsoft Word文档。当用户点击新建Microsoft Word 97 – 2003 文档时,就会创建出
一个.doc文件;而用户点击新建Microsoft Word 文档时,就会创建出一个.docx文件,实际上Microsoft Word 2007及之后的Word版本还支持.docm文件,那么这三种文件有什么区别呢?
.doc文件是一种普通的OLE文件(复合文件),能够包含宏。而.docx和.docm文件,实际上都是压缩文件。
实际上.docx主要的内容基本都存在于word目录下,比较重要的有以下的内容:
- document.xml:记录Word文档的正文内容
- footer*.xml:记录Word文档的页脚
- header*.xml:记录Word文档的页眉
- comments.xml:记录Word文档的批注
- footnotes.xml:记录Word文档的脚注
- endnotes.xml:记录Word文档的尾注
利用同样的方式打开.docm文件,可以发现和.docx文件的内容基本相同,但是比.docx文件多了一个文件:vbaProject.bin,这是一个复合文件,记录vba工程信息。
1.1.1.1 基础知识
OLE文件数据的存储结构和磁盘数据的存储结构有很大的相似性,都是以扇区为单位进行存储的,但二者的扇区是截然不同的。对于一个doc文件,其实质是一复合二进制文件(OLE文件),用Office Visualization Tool 载入.doc文件,可以看到清晰的文件结构,如图所示:

- 文件头Header
固定的512字节。Header中记录着文件解析必须的所有参数。Header之后的区域是不同的Sector。

下表是对图中这512字节的解析:
| 字节偏移 | 值 | 说明 |
| 0x00H~0x07H | 0xD0 0xCF 0x11 0xE0
0xA1 0xC1 0x1A 0xE1 |
8个字节:固定值:0xD0 0xCF 0x11 0xE0 0xA1 0xB1 0x1A0xE1,表示此文件是复合文件 |
| 0x08H~0x17H | 0x00 0x00 0x00 0x00
0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
16个字节:ClassID,不过很多文件都置0 |
| 0x18H~0x19H | 0x3E 0x00 | 2个字节:一般为0x3E,表示文件格式的修订号 |
| 0x1AH~0x1BH | 0x03 0x00 | 2个字节:一般为0x3,表示文件格式的版本号 |
| 0x1CH~0x1DH | 0FE 0xFF | 2个字节:一般0FE 0xFF,表示文档使用的存储格式是小端模式(理论上0xFF 0xFE则表示大端存储方式) |
| 0x1EH~0x1FH | 0x09 0x00 | 2个字节:默认值:0x09 0x00,表示Sector的大小,当值为9时,即每个Sector为512(29)字节 |
| 0x20H~0x21H | 0x06 0x00 | 2个字节:默认值:0x06 0x00,表示Mini-Sector的大小,当值为6时,即每个Mini-Sector为64(26)字节 |
| 0x22H~0x23H | 0x00 0x00 | 2个字节,UInt16,预留值,置0 |
| 0x24H~0x27H | 0x00 0x00 0x00 0x00 | 4个字节,UInt32,预留值,置0 |
| 0x28H~0x2BH | 0x00 0x00 0x00 0x00 | 4个字节:表示目录扇区Directory Sectors的数量的数量;若版本号为3,则该值为0 |
| 0x2CH~0x2FH | 0x01 0x00 0x00 0x00 | 4个字节:表示FAT的数量 |
| 0x30H~0x33H | 0x28 0x00 0x00 0x00 | 4个字节:表示Directory开始的SectorID文件目录流的起始扇区编号 |
| 0x34H~0x37H | 0x00 0x00 0x00 0x00 | 4个字节:一般置0,用于事务 |
| 0x38H~0x3BH | 0x00 0x10 0x00 0x00 | 4个字节:表示ulMiniSectorCutoff,是最小串(Stream)的最大大小,默认为4096(0x00 0x10 0x00 0x00) |
| 0x3CH~0x3FH | 0x2A 0x00 0x00 0x00 | 4个字节:_sectMiniFatStart ,是MiniFAT表开始的SectorID |
| 0x40H~0x43H | 0x01 0x00 0x00 0x00 | 4个字节:表示MiniFAT表的数量 |
| 0x44H~0x47H | 0xFE 0xFF 0xFF 0xFF | 4个字节:表示DIFAT开始的SectorID,DIFAT的起始扇区编号 |
| 0x48H~0x4BH | 0x00 0x00 0x00 0x00 | 4个字节:表示DIFAT的数量 |
| 0x4CH~0x1FFH | 0x27 0x00 0x00 0x00
0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF … 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF |
436个字节:UInt32,包含了109个DIFAT,每个DIFAT占用4个字节,是前109块FAT表的SectorID。Header中存储的了109个DIFAT数据。但是有时候109个还不够,这时候可以使用其它扇区专门存储DIFAT数据,0x44H~0x47H中记录的就是除这109项外,其他的DIFAT数据的起始扇区编号。在DIFAT扇区的最后4个字节,存储了下个DIFAT扇区的ID,以表示下个DIFAT数据的存储位置 |
3. Sector(扇区)
一般是512字节,是实际数据存储的地方,复合文档中数据都是以扇区为单位进行存储的。扇区有两种Sector和Mini-Sector(Sector:扇区,一般是512字节;MiniSector:短扇区,64字节)。扇区内存储的数据有种类有Stroage、Stream、Directory、FAT、Mini-FAT(属于Mini-Sector)、DIF等,但每个扇区中只能存储一种数据类型。每个Sector都有一个SectorID,但是Header所在的扇区ID是-1,并不是0。Header后的Sector才是“第一个”Sector,其SectorID为0。
4. Storage与Stream
他们的功能相当于文件系统中的文件夹与文件的功能。Storage中是没有任何“实质性”的内容的,只会记录其包含的Stream和Storage,是一个Stream和Storage的目录。“实质性”的内容全在Stream里面。
5. Directory
中文“目录”,和Storage的“目录”功能有着很大区别,Directory是一个Storage和Stream的索引。这一部分存储空间是用来记录Storage和Stream的存储结构以及名称、大小、起始地址等信息。
044H到047H的4字节指出Directory起始扇区,根据FAT表找到接下来的扇区。
复合文档从字面上理解就是很多内容放在一起复合形成文档,这么多内容当然需要有个目录,而Directory就是这个目录。Directory起始的SectorID需要从Header中读取,定位的方法在上文中提到(512+ 扇区大小 * 扇区ID)。Directory中每个DirectoryEntry固定为128字节,其主要结构如表所示:
| 偏移 | 描述 |
| 0x00H~0x3FH | 64个字节:存储DirectoryEntry名称的,并且是以Unicode存储的,即每个字符占2个字节, |
| 0x40H~0x41H | 2个字节:DirectoryEntry名称的长度(包括最后的“\0”) |
| 0x42H~0x42H | 1个字节:是DirectoryEntry的类型。0为非法,1为目录(storage),2为节点(Stream),5为根节点(Root Entry即第一个目录内容) |
| 0x43H~0x43H | 1个字节:节点的颜色 |
| 0x44H~0x47H | 4个字节:该DirectoryEntry左兄弟的EntryID(第一个DirectoryEntry的EntryID为0,下同) |
| 0x48H~0x4BH | 4个字节:该DirectoryEntry右兄弟的EntryID |
| 0x4CH~0x4FH | 4个字节:该DirectoryEntry一个孩子的EntryID |
| 0x50H~0x5FH | 16个字节:表示CLSID |
| 0x60H~0x63H | 4个字节:表示UserFlags,一般是0 |
| 0x64H~0x6BH | 8个字节:表示文件创建时间 |
| 0x6CH~0x73H | 8个字节:表示文件修改时间 |
| 0x74H~0x77H | 4个字节:表示该DirectoryEntry开始的SectorID |
| 0x78H~0x7BH | 4个字节:是该DirectoryEntry存储的所有字节长度 |
| 0x7CH~0x7FH | 4个字节:保留置0 |
Directory为Storage的有clsid、time、和sidChild, 可能没有stream。Stream有个有效的sectdtart和ulsize,但是storage的是0。
当usize小于ulMiniSectorCutoff时,表示stream使用的是MiniFat。
常见的Directory有很多,比较重要的有root entry、WordDocument、1Table、SummaryInformation、DocumentSummaryInformation、Macros和Vba。
root entry是Directory里的第一个内容,只是作为根节点,有些文档中直接命名为R,接下来的介绍WordDocument、1Table、SummaryInformation、DocumentSummaryInformation、Macro都是位于root entry节点下的,其中Vba位于Orphaned节点下。
DocumentSummaryInformation和SummaryInformation是摘要信息。
对于DocumentSummaryInformation,其结构如表所示
| 偏移 | 值 | 描述 |
| 0x18~0x1B | 4字节,UInt32 | 存储属性组的个数 |
| 0x1C~0x28 | 0x02 0xD5 0xCD 0xD5 0x9C 0x2E 0x1B 0x10 0x93 0x97 0x08 0x00 0x2B 0x2C 0xF9 0xAE | DocumentSummaryInformation |
| 0x05 0xD5 0xCD 0xD5 0x9C 0x2E 0x1B 0x10 0x93 0x97 0x08 0x00 0x2B 0x2C 0xF9 0xAE | UserDefinedProperties | |
| 0xE0 0x85 0x9F 0xF2 0xF9 0x4F 0x68 0x10 0xAB 0x91 0x08 0x00 0x2B 0x27 0xB3 0xD9 | SummaryInformation | |
| 0x29~0x2C | 4字节UInt32 | 属性组相对于Entry的偏移 |
对于每个属性组,其结构如下:
- 0x00H~0x03H:是属性组大小。
- 0x04H~0x07H:是属性组中属性的个数。
- 从008H开始的每8字节,是属性的信息:
前4字节:属性的种类。
后4字节:属性内容相对于属性组的偏移。
常见的属性编号如表所示:
| 属性 | 值 | 属性 | 值 |
| Unknown | 0x00 | Scale | 0x0B |
| CodePage | 0x01 | HeadingPairs | 0x0C |
| Category | 0x02 | DocumentParts | 0x0D |
| PresentationTarget | 0x03 | Manager | 0x0E |
| Bytes | 0x04 | Company | 0x0F |
| LineCount | 0x05 | LinksDirty | 0x10 |
| ParagraphCount | 0x06 | CountCharsWithSpaces | 0x11 |
| Slides | 0x07 | SharedDoc | 0x13 |
| Notes | 0x08 | HyperLinksChanged | 0x16 |
| HiddenSlides | 0x09 | Version | 0x17 |
| MMClips | 0x0A | ContentStatus | 0x1B |
对于每个属性,其结构如下:
① 0x00H~0x03H:属性内容的类型,值有:
0x02表示UInt16
0x03表示UInt32
0x0B表示Boolean
0x1E表示String
② 属性组中剩下的字节是属性的内容,当属性组中内容类型是String时,剩下字节不定长,剩下三种类型都是4个字节(多余字节置0)。
“WordDocument”和“1Table”是专门存储文档内容的DirectoryEntry。需要说明的是,Word中的存储文档内容的DirectoryEntry与PowerPoint和Excel中都不同,Word中是“WordDocument”和“1Table”,PowerPoint是“PowerPoint Document”,Excel是“Workbook”。
对于WordDocument,其最重要的应该是其中包含的FIB(File Information Block)了,FIB位于WordDocument的开头,其包含着Word文件非常重要的参数,诸如文件的加密方式、文字的编码等等。
FIB是可变长的,开头是固定32字节长的FibBase:
0x00H~0x01H:0xA5EC(0xEC 0xA5),表示Word二进制文件。
0x02H~0x03H:一般是0xC1,表示Word97版本,表示最低版本

0x0AH~0x0BH:16bit,被分成了13部分。除了第5部分占了4bit外,其余12部分各站1bit,总计16bit。说明下13部分是如何分配的,最左为最低位。
A:为文档是否是.Dot文件(Word模板文件)
B:目前该位没有解析出含义。
C:文档快速保存时生成的格式。
D,文档中是否存在图片。
E,快速保存的次数。
F,文档有没有加密。
G,文字存储的位置,为1表示1Table,为0表示0Table。
H,是否只读方式代开
I,是否含有写保护密码。
J,固定值1。
K,应用程序默认的语言和字体。
L,文档语言是东亚语言。
M,文档加密方式,1表示异或混淆,0则是其他加密方式;如果文档未加密则忽略该值。
0x0CH~0x0DH:一般为0x00BF,少数是0x00C1。
0x0EH~0x11H:文档加密的密钥;否则应置0。
0x12H~0x12H:置0。
0x13H~0x13H:16bit被划分为6部分
第1位:0。
第2位:新建文件的方式。
第3位:页面默认的格式。
第4位:忽略
第5位:忽略。
第6-8位:忽略。
014H~017H:置0,忽略。
018H~01FH:忽略。
FIB中内容仍然有很多,但是了解上述内容就可以读取文档的内容,之后的部分就不再介绍了。
“1Table”和“0Table”也是存储文档内容的目录,有时候也被叫做Table Stream,Table Stream其实是他们的总称,根据FIB中的信息判断文字存于“1Table”还是“0Table”。但是目前仍然不知道文字存储与哪一个扇区中。这些信息都存放在Table Stream中的Piece Table中,Piece Table的位置可以从FIB中获取到。
Piece Table结构为:
0x00H~0x00H:固定值0x02,Piece Table的标识。
0x01H~0x04H:是Piece Table的大小。
Piece Table中数量的计算公式:
n=(Piece Table的大小 – 4)/(4 + Piece Element的大小)
随后的4*(n + 1)个字节,存储Piece Element中存储的文本的开始位置(结束位置即下一个的开始位置)。
之后的8*n个字节,存储每个Piece Element的信息。
由此可以获取Word中文本的存储位置,文字是按下面的顺序存储的:
正文内容(Main document)
脚注(Footnote subdocument)
页眉和页脚(Header subdocument)
批注(Comment subdocument)
尾注(Endnote subdocument)
文本框(Textbox subdocument)
页眉文本框(Textbox Subdocument of the header)
Macro和Vba的解析与WordDocument的解析类似,需要注意的是其Type标志为1。
5. FAT是索引表
数据在硬盘上的存储是离散的,需要有一个索引表能找到这些数据,索引表中存放着数据的起始地址(即扇区的),其实每一条索引也是离散的,索引中一般还有一条数据指向下一条索引,类似于链表。FAT实际记录了该扇区指向的下一个扇区的地址。
由上文中对Header部分的分析可以得知,0x4CH~0x4FH记录的是DIFFAT[0],即第一个FAT表的SectorID, 在图中0x4CH~0x4FH处的值为0x27,经过计算:FAT表的偏移=0x200H+0x27H×0x200H=0x5000H。

由图可以得知FAT[0]=1,FAT[1]=2……FAT记录了该扇区指向的下一个扇区ID。
但是也有FAT[7]=0xFFFFFFFE,这样的数据,但0x0FFFFFFFE并不是某个扇区的ID,实际上这表示ID为7的扇区是结束扇区!
前文已述一个扇区能且只能存放一种类型的数据,但是复合文档怎么知道扇区中存储的是哪一种类型的数据?因而在复合文档的FAT数据中,除了表示扇区ID的数字,还有些特殊的数字ID表示一些特定的扇区,详细介绍见表:
| 类型 | ID值 | 描述 |
| REGSECT | 0x00000000-0xFFFFFFF9 | 正常的数据扇区ID,表示下一个数据扇区 |
| MAXREGSECT | 0xFFFFFFFA | 扇区ID最大值 |
| Not applicable | 0xFFFFFFFB | 保留扇区ID |
| DIFSECT | 0xFFFFFFFC | DIFAT扇区ID,表示该扇区存储了DIFAT的数据 |
| FATSECT | 0xFFFFFFFD | FAT扇区ID,表示该扇区存储了FAT的数据 |
| ENDOFCHAIN | 0xFFFFFFFE | 结束字符 |
| FREESECT | 0xFFFFFFFF | 空扇区ID |
由前文可知FAT所在的扇区ID是27,查表可知FAT扇区用0xFFFFFFFD表示,所以FAT[27]=0xFFFFFFFD,对照图,果然如此。
一个扇区大小为512字节,一组FAT信息占据4个字节。因而一个FAT扇区中,最多能够存放128组FAT信息,可以利用DIFAT列表把不同的FAT扇区串联起来。FAT信息在一个扇区内部的存储都是连续的。比如某个FAT扇区,第1组FAT信息代表的扇区的ID是3的话,则这个扇区可以表示的扇区ID范围是3到131。
MINIFAT的解析,其方法和FAT类似,其起始扇区ID存放在Header信息中,MINIFAT表的顺序,当记录在FAT中,这里就不赘述了。
6. DIFAT是分区表,是FAT的索引表。
FAT也是存储在Sector里面,但是FAT本身也比较大,所以利用DIFAT作为FAT的索引表,记录了FAT所在的Sector的起始地址以及逻辑关系。
7. 补充
在Word中,WordDocument永远是Header后的第一个扇区,但是PowerPoint Document不一定。不过,PowerPoint的数据都存储在PowerPoint Document中。
PowerPoint以Record为基础存储的内容。Record有Container Record和Atom Record两种。类似于Sector中的 Stroge和Stream,Container Record是容器,Atom Record是容器中的内容,那么其实PowerPoint Document中存储结构也类似于WordDocument的其实也就是树形结构。
对于每一个Record,其结构如下:
0x00H~0x01H:Record的版本,其中低4位是recVer(如果是0x0F则一定为Container),高12位是recInstance。
0x02H~0x03H:Record的类型recType。
0x04H~0x07H:Record内容的长度recLen。
剩下的字节是Record的具体内容。
由于PowerPoint支持上百种Record,表举一些常用的Record:
| 值(16进制) | 值(10进制) | 描述 |
| 0x03E8 | 1000 | DocumentContainer |
| 0x0FF0 | 4080 | MasterListWithTextContainer/SlideListWithTextContainer/NotesListWithTextContainer |
| 0x03F3 | 1011 | MasterPersistAtom/SlidePersistAtom/NotesPersistAtom |
| 0x0F9F | 3999 | TextHeaderAtom |
| 0x03EA | 1002 | EndDocumentAtom |
| 0x03F8 | 1016 | MainMasterContainer |
| 0x040C | 1036 | DrawingContainer |
| 0x03EE | 1006 | SlideContainer |
| 0x0FD9 | 4057 | SlideHeadersFootersContainer/NotesHeadersFootersContainer |
| 0x03EF | 1007 | SlideAtom |
| 0x03F0 | 1008 | NotesContainer |
| 0x0FA0 | 4000 | TextCharsAtom |
| 0x0FA8 | 4008 | TextBytesAtom |
| 0x0FBA | 4026 | CString,储存很多文字的Atom |
1.1.2 宏代码数据结构解析

文档中的宏代码数据是分段存储的,每段最大是0xFFF字节,图中红框框起来的1.5个字节表示此段宏代码数据的长度:0x1*0x100+0x17=0x117,0x17、0xB1后的数据就是宏代码数据(包含宏属性信息)。
宏代码里的数据是按组进行划分的,每组包括一个字节的标志,和8个元素
| Flag | 0x01 | 0x02 | 0x04 | 0x08 | 0x10 | 0x20 | 0x40 | 0x80 |
| 标志字 | 元素1 | 元素2 | 元素3 | 元素4 | 元素5 | 元素6 | 元素7 | 元素8 |
一般来说一个元素对应一个字节,标志字Flag的每一位对应一个元素,表示这一个元素的具有两个字节。
如图第一组“0x00 0x41 0x74 0x74 0x72 0x69 0x62 0x75 0x74”,Flag=0x00,每一个元素对应的标志位都是0,所以每一个元素都对应一个字节:
| 元素1 | 元素2 | 元素3 | 元素4 | 元素5 | 元素6 | 元素7 | 元素8 |
| 0x41 | 0x74 | 0x74 | 0x72 | 0x69 | 0x62 | 0x75 | 0x74 |
第五组“0x10 0x74 0x22 0x0D 0x0A 0x0A 0x8C 0x42 0x61 0x73”,Flag=0x10,元素5对应的标志位是1,其他元素都是0,所有元素五对应2个字节,其他元素都对应一个字节
| 元素1 | 元素2 | 元素3 | 元素4 | 元素5 | 元素6 | 元素7 | 元素8 |
| 0x74 | 0x22 | 0x0D | 0x0A | 0x0A0x8C | 0x42 | 0x61 | 0x73 |
在解析宏代码时,就是把这些元素拼接起来,组成完整的宏代码。
- 分析前4组的数据,我们可以拼接出数据 data=“Attribute VB_Name=”ThisDocumen”。
- 我们继续加入第5组的数据,添加到元素5时,我们就遇到了麻烦,元素5具有2个字节。对于两个字节为一个元素的,先计算已经识别出的宏代码长度L,计算T=log2(L),T<4,则设置T=4;T>12,设置T=12,这里计算T=6。
0x0A 0x8C被识别为整数0x8C0A,然后计算:
offset=1+(0x8C0A>>(16-T))#=0x24
length=3+(((0x8C0A<<T)&0xFFFF)>>T)#=0xB=13
copy=data[-offset:]
copy=copy[0:length]
lengthCopy = len(copy)
while length > lengthCopy: #a#
if length – lengthCopy >= lengthCopy:
copy += copy[0:lengthCopy]
length -= lengthCopy
else:
copy += copy[0:length – lengthCopy]
length -= length – lengthCopy
data += copy
如此我们便计算出前5组数据的宏代码data=“Attribute VB_Name=”ThisDocumen” \r\nAttribute VB_Bas”。
如此我们就能计算出0xD3长度的第一段宏代码数据的内容,计算完第一段数据后,紧跟着的就是第二段宏代码数据,我们可以用同样的方式进行计算,不过这个显示第二段宏代码数据的长度为0,说明本文档中没有第二段宏代码数据。

宏病毒处理思路
2.1 破坏宏标志
在解析OLE文件时,我们介绍过Directory,其中其偏移0x42H这个字节的表示DirectoryEntry的类型Type。0为非法,1为目录(storage),2为节点(Stream),5为根节点。
我们可以定位宏工程所使用的Directory,将Type位修改为0,即非法Directory,这样Office办公软件在解析VBA工程时,会因为非法Directory而导致解析错误。
如图所示,表示该扇区类型的字节记录在偏移0x42处,该处值为1,表示该扇区是目录扇区,该扇区记录着Macros文件的地址。将偏移0x42处值修改为0,表示该扇区是非法扇区,office办公软件解析文档是就会忽略该扇区,也就无法找到存储Macros的扇区了。

在上图中,我们值修改了名为“Macros”的这个Directory。实际上,用于宏的Directory还有两个,分别名为”VBA”,和”_VAB_PROJECT_CUR”,分别是macros、VBA和vbaproject扇区。

